-
[이취코] ch05. 탐색 알고리즘 DFS/BFSMajor/Algorithms 2022. 3. 28. 23:15
탐색 알고리즘을 알기 전에 먼저 그래프의 기본 구조를 알아야한다
그래프는 노드(Node)와 간선(edge)로 표현되며, 이 때 노드를 정점(Vertex)라고도 말한다.
간선으로 연결되어 있는 노드들은 "인접한 노드" 라고 표현한다
프로그래밍에서 그래프를 표현하는 방식은 2가지이다. 모두 알고있도록 하자
(1) 인접 행렬 (Adjacency Matrix) : 2차원 배열로 그래프의 연결 관계를 표현하는 방식
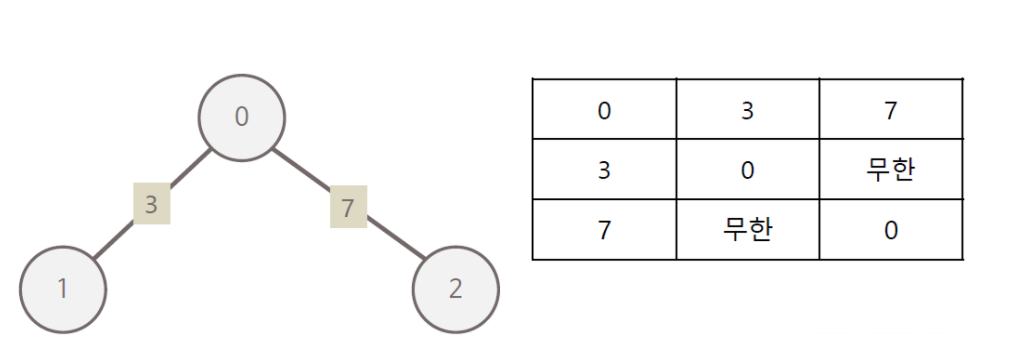
사진 출처 https://velog.io/@underlier12/자료구조-학습-08-6pk5kzgbup 이렇게 연결된 노드들을 행렬로 표현하고, 연결되어 있지 않은 노드들은 무한의 비용이라고 작성한다
코드로 인접행렬을 작성하면
#include <iostream> #define INF 999999999 // 무한의 비용 선언 using namespace std; // 2차원 리스트를 이용해 인접 행렬 표현 int graph[3][3] = { {0, 7, 5}, {7, 0, INF}, {5, INF, 0} }; int main(void) { // 그래프 출력 for (int i = 0; i < 3; i++) { for (int j = 0; j < 3; j++) { cout << graph[i][j] << ' '; } cout << '\n'; } }2차원 리스트를 이용해 선언해주고 출력해주기만 하면 된다.
(2) 인접 리스트 (Adjacency List) : 리스트로 그래프의 연결 관계를 표현하는 방식

사진 출처 https://velog.io/@ase0574/인접-행렬과-인접-리스트 인접 리스트는 모든 노드에 연결된 노드에 대한 정보를 차례대로 연결하여 저장한다
'연결리스트' 라는 자료구조를 이용해 구현하는데, cpp이나 java에서는 별도로 연결리스트 기능을 위한 표준 라이브러리를 제공한다
코드로 구현하면
#include <iostream> #include <vector> using namespace std; // 행(Row)이 3개인 인접 리스트 표현 vector<pair<int, int> > graph[3]; int main(void) { // 노드 0에 연결된 노드 정보 저장 {노드, 거리} graph[0].push_back({1, 7}); graph[0].push_back({2, 5}); // 노드 1에 연결된 노드 정보 저장 {노드, 거리} graph[1].push_back({0, 7}); // 노드 2에 연결된 노드 정보 저장 {노드, 거리} graph[2].push_back({0, 5}); // 그래프 출력 for (int i = 0; i < 3; i++) { for (int j = 0; j < graph[i].size(); j++) { cout << '(' << graph[i][j].first << ',' << graph[i][j].second << ')' << ' '; } cout << '\n'; } }두 방식의 차이점?
인접행렬 - 모든 관계를 저장하므로 노드 개수가 많을 수록 메모리 불필요하게 낭비
인접리스트 - 연결된 정보만을 저장하기 때문에 메모리 효율적
but 인접 리스트 방식은 연결된 데이터를 하나씩 확인해야하기 때문에 정보를 얻는 속도가 느리다
DFS
DFS : Depth - First Search
DFS는 깊이 우선 탐색이라고도 부르며, 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이다
→ 특정한 경로로 탐색하다가 특정한 상황에서 최대한 깊숙이 들어가서 노드를 방문한 후, 다시 돌아가 다른 경로로 탐색
→ 스택 자료구조를 이용
동작 과정
(1) 탐색 시작 노드를 스택에 삽입하고 방문 처리
(2) 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고 방문 처리
방문하지 않은 인접노드가 없으면 스택에서 최상단 노드를 꺼낸다
(3) (2)의 과정을 더 이상 수행할 수 없을때까지 반복
* 일반적으로 낮은 번호부터 노드 방문처리를 한다
step 1. 시작노드인 '1'을 스택에 삽입하고 방문 처리를 한다

step 2. 스택의 최상단 노드인 '1'에 방문하지 않은 인접노드 '2', '3', '8'이 있다. 이중에서 가장 작은 노드인 '2' 를 스택에 넣고 방문 처리
* 방문 처리 된 노드는 회색으로, 현재 처리하는 스택의 최상단 노드는 하늘색으로 표현한다
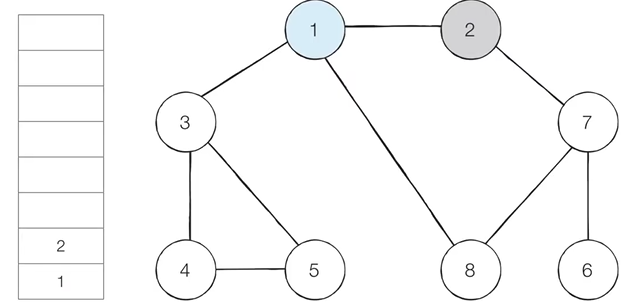
step 3. 스택의 최상단 노드인 '2'에 인접한 노드 중 방문하지 않은 노드 '7'이 있다. '7'을 스택에 삽입하고 방문 처리
step 4. 스택의 최상단 노드인 '7'에 인접한 노드 '8','6' 중에 '6'이 더 작으므로 '6'을 스택에 삽입하고 방문처리
step 5. 스택의 최상단 노드인 '6'은 인접한 노드가 없다. 따라서 스택에서 '6'을 꺼낸다. 그럼 스택의 최상단 노드는 다시 '7'이 된다
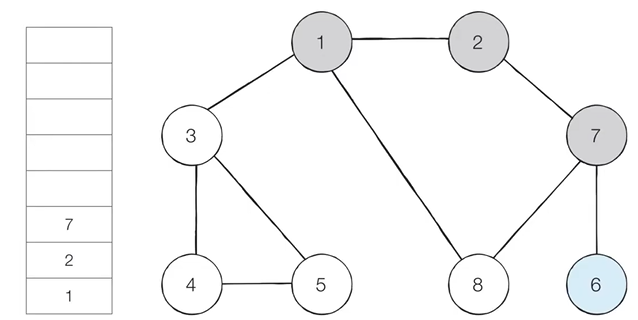
이 방식으로 모든 노드의 방문처리를 반복하면
결과적으로 노드의 탐색 순서 (스택에 들어간 순서)는 1 - 2 - 7- 6 - 8 - 3 - 4- 5
코드로 구현하면
#include <iostream> #include <vector> using namespace std; bool visited[9]; vector<int> graph[9]; // DFS 함수 정의 void dfs(int x) { // 현재 노드를 방문 처리 visited[x] = true; cout << x << ' '; // 현재 노드와 연결된 다른 노드를 재귀적으로 방문 for (int i = 0; i < graph[x].size(); i++) { int y = graph[x][i]; if (!visited[y]) dfs(y); } } int main(void) { // 노드 1에 연결된 노드 정보 저장 graph[1].push_back(2); graph[1].push_back(3); graph[1].push_back(8); // 노드 2에 연결된 노드 정보 저장 graph[2].push_back(1); graph[2].push_back(7); // 노드 3에 연결된 노드 정보 저장 graph[3].push_back(1); graph[3].push_back(4); graph[3].push_back(5); // 노드 4에 연결된 노드 정보 저장 graph[4].push_back(3); graph[4].push_back(5); // 노드 5에 연결된 노드 정보 저장 graph[5].push_back(3); graph[5].push_back(4); // 노드 6에 연결된 노드 정보 저장 graph[6].push_back(7); // 노드 7에 연결된 노드 정보 저장 graph[7].push_back(2); graph[7].push_back(6); graph[7].push_back(8); // 노드 8에 연결된 노드 정보 저장 graph[8].push_back(1); graph[8].push_back(7); dfs(1); }깊이 우선 탐색인 DFS는 스택 자료구조에 기초한다는 점에서 구현이 간단하다
실제로는 스택을 쓰지 않아도 되며 탐색을 수행하는데 데이터의 개수가 N개인 경우 O(N)의 시간이 소요된다
DFS는 스택을 사용하기 때문에 실제 구현은 재귀함수를 이용하면 매우 간단하다
BFS
BFS: Breadth First Search
BFS는 너비 우선 탐색이다 / 가까운 노드부터 탐색하는 알고리즘
선입선출 방식인 큐 자료구조를 이용한다
동작방식
(1) 탐색 시작 노드를 큐에 삽입하고 방문처리
(2) 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리
(3) 2번의 과정을 더 이상 수행할 수 없을 때까지 반복
DFS 때와 같은 그래프가 있다고 해보자
step 1. 시작노드인 '1'을 큐에 삽입하고 방문처리
* 회색 - 방문처리 된 노드 / 하늘색 - 큐에서 꺼내 현재 처리하는 노드
step 2. 큐에서 1을 꺼내고 인접한 노드 2,3,8을 큐에 삽입, 방문처리 (가까운 노드부터! - 너비 우선 탐색)

step 3. 큐에서 2를 꺼내고 인접한 노드 7을 큐에 삽입, 방문처리
step 4. 큐에서 3을 꺼내고 인접한 노드 4, 5 를 큐에 삽입, 방문처리
step 5. 큐에서 8을 꺼내고 인접한 노드가 없으므로 무시

step 6. 큐에서 7을 꺼내고 인접한 노드 6을 큐에 삽입, 방문처리
step 7. 모든 노드 방문처리가 되었으므로 큐에 남은 4,5,6 모두 꺼내기
결론적으로 탐색 순서는 1 -2 - 3 - 8 - 7 - 4 - 5 -6
코드로 구현하면
#include <iostream> #include <vector> using namespace std; bool visited[9]; vector<int> graph[9]; // BFS 함수 정의 void bfs(int start) { queue<int> q; q.push(start); // 현재 노드를 방문 처리 visited[start] = true; // 큐가 빌 때까지 반복 while(!q.empty()) { // 큐에서 하나의 원소를 뽑아 출력 int x = q.front(); q.pop(); cout << x << ' '; // 해당 원소와 연결된, 아직 방문하지 않은 원소들을 큐에 삽입 for(int i = 0; i < graph[x].size(); i++) { int y = graph[x][i]; if(!visited[y]) { q.push(y); visited[y] = true; } } } } int main(void) { // 노드 1에 연결된 노드 정보 저장 graph[1].push_back(2); graph[1].push_back(3); graph[1].push_back(8); // 노드 2에 연결된 노드 정보 저장 graph[2].push_back(1); graph[2].push_back(7); // 노드 3에 연결된 노드 정보 저장 graph[3].push_back(1); graph[3].push_back(4); graph[3].push_back(5); // 노드 4에 연결된 노드 정보 저장 graph[4].push_back(3); graph[4].push_back(5); // 노드 5에 연결된 노드 정보 저장 graph[5].push_back(3); graph[5].push_back(4); // 노드 6에 연결된 노드 정보 저장 graph[6].push_back(7); // 노드 7에 연결된 노드 정보 저장 graph[7].push_back(2); graph[7].push_back(6); graph[7].push_back(8); // 노드 8에 연결된 노드 정보 저장 graph[8].push_back(1); graph[8].push_back(7); bfs(1); }BFS는 큐의 자료구조를 사용한다는 점에서 구현이 간단하다
구현하는데 deque 라이브러리를 사용하는 것이 좋으며 수행하는데 O(N)이 시간이 소요된다
일반적인 경우 실제 수행시간은 DFS보다 좋은편이다 (DFS는 재귀함수이기 때문)
간단히 정리하자면
DFS BFS 동작 원리 스택 큐 구현 방법 재귀 함수 큐 자료구조 이용 DFS/BFS 문제는 그래프 유형으로 생각하면 풀기 쉽다
코딩테스트 중 2차원 배열에서의 탐색 문제를 만나면 그래프형태로 바꿔서 생각해보자!
'Major > Algorithms' 카테고리의 다른 글
[이취코] ch06-2. 삽입 정렬 (Insertion Sort) (0) 2022.03.30 [이취코] ch06-1. 선택정렬 (Selection Sort) (0) 2022.03.30 [이취코] ch05. 자료구조 기초 (스택/큐/재귀함수) (0) 2022.03.22 [이취코] ch04. 구현 유형 문제 풀이 (0) 2022.03.15 [이취코] 04. 구현 유형 개요 (0) 2022.03.15